Optimizing Deep Learning Inference via Global Analysis and Tensor Expression
Apr 29, 2024· ,,,,,·
0 min read
,,,,,·
0 min read
Chunwei Xia
Jiacheng Zhao
Qianqi Chen
Zheng Wang
Xiaobing Feng
Huimin Cui
 Tensor Compiler
Tensor CompilerAbstract
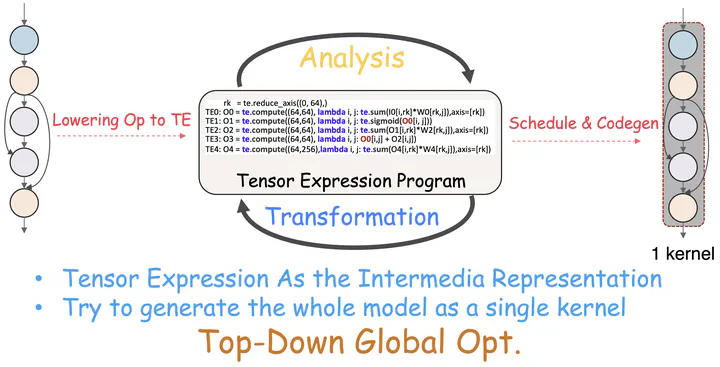
Optimizing deep neural network (DNN) execution is important but becomes increasingly difficult as DNN complexity grows. Existing DNN compilers cannot effectively exploit optimization opportunities across operator boundaries, leaving room for improvement. To address this challenge, we present Souffle, an open-source compiler that optimizes DNN inference across operator boundaries. Souffle creates a global tensor dependency graph using tensor expressions, traces data flow and tensor information, and partitions the computation graph into subprograms based on dataflow analysis and resource constraints. Within a subprogram, Souffle performs local optimization via semantic-preserving transformations, finds an optimized program schedule, and improves instruction-level parallelism and data reuse. We evaluated Souffle using six representative DNN models on an NVIDIA A100 GPU. Experimental results show that Souffle consistently outperforms six state-of-the-art DNN optimizers by delivering a geometric mean speedup of up to 3.7× over TensorRT and 7.8× over Tensorflow XLA.
Type
Publication
In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems